Matching
AVM が software を affected と判断するまで
AVM の matching は、software names と CVE records の単純な文字列比較ではありません。 canonical identification、structured vulnerability conditions、 そして version-aware evaluation を組み合わせることで、 review 可能な alert results を生成します。
Matching は名前比較だけではない
AVM は、assets に紐付いた observed software records から始まります。 これらの software rows には、 vendor、product、version などの raw inventory values が保持されます。 vulnerability matching を信頼できる形で行うには、 まず各 software row を canonical vendor / product references に link しようとします。
canonical linkage ができた後、 AVM は stored vulnerability conditions を評価します。 ここでは、affected CPE relationships、 structured criteria trees、version-range evaluation などが使われます。 結果は単純に「同じ名前だから affected」ではありません。 identity、conditions、利用可能な evidence に基づく判断です。
Key point: product similarity だけでは不十分です。 AVM は、その vulnerability が実際に適用されるかを評価するよう設計されています。
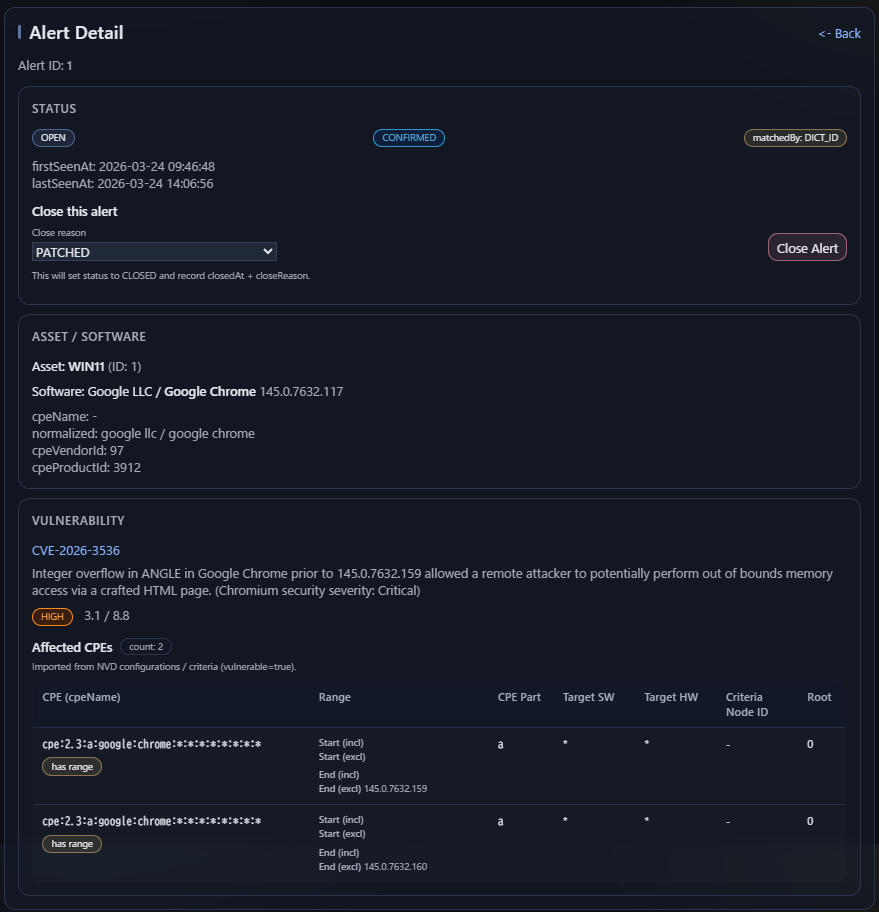
Matching pipeline
1. Raw inventory を収集する
AVM は import sources から、 vendor、product、publisher、version などの software observations を受け取ります。
2. Canonical linking を解決する
raw names を canonical vendor / product references に結び付けることで、 matching が不安定な source-side strings のみに依存しないようにします。
3. Vulnerability conditions を読み込む
AVM は、stored vulnerabilities に対応する affected CPE relationships と structured criteria definitions を読み込みます。
4. Criteria logic を評価する
matching logic は、すべてを単純な名前リストに flatten するのではなく、 relevant predicates として評価します。
5. Version conditions を確認する
version-aware evaluation により、 名前だけは似ている software と、 実際に affected である software を区別しやすくなります。
6. Alerts を作成または更新する
条件が満たされた場合、 AVM はその software と vulnerability の組み合わせに対する operational alert state を作成または更新します。
Matching が参照するもの
matching decision は、一つの field ではなく、 複数種類のデータに基づいています。
Raw inventory values
source system から観測された vendor、product、publisher、version などの値です。
Canonical references
comparison target を安定させるための canonical vendor / product identities です。
Vulnerability intelligence
affected CPE pairs や structured criteria definitions を含む stored vulnerability records です。
Version evidence
該当する場合に version-range evaluation に使われる installed version information です。
なぜ canonical linking が先に必要なのか
inventory sources は、めったに一つの安定した naming style を使いません。 同じ vendor や product が、 tool、operating system、collection method の違いによって 複数の形で現れることがあります。 AVM は vulnerability matching に進む前に、 raw software rows を canonical vendor / product records に linking することで、 その曖昧さを減らします。
これが、unresolved mappings が visible review surface として扱われる理由でもあります。 canonical identity が不明瞭なままであれば、 downstream matching がそれ以上に確実そうに見えるべきではありません。
Canonical linking がない場合
matching は、一貫しない raw strings に過度に依存してしまいます。
Canonical linking がある場合
matching は、imports や review cycles をまたいで再利用できる normalized product identity を対象にできます。
Affected CPEs と criteria trees
AVM は、脆弱性の適用条件を一種類だけで保持しているわけではありません。 一部の評価では affected canonical CPE relationships を直接使えますが、 別のケースでは structured criteria の評価が必要になります。
Affected CPE relationships
これは、ある vulnerability に関連することが分かっている canonical vendor / product combinations を表します。 direct lookups や candidate filtering に役立ちます。
Criteria tree structure
これは vulnerability conditions の logical structure を保持するもので、 AVM がそれらを flat list に落とさず、 predicates として評価できるようにします。
Criteria CPE predicates
これは criteria nodes に紐付く、 specific CPE-based conditions を表します。 version evaluation に関係する情報も含まれます。
これは重要です。 実際の vulnerability applicability は条件付きであることが多いからです。 ある vulnerability は、 product identity、platform scope、version range をまとめて満たす必要がある場合があります。
なぜ criteria が重要なのか
vulnerability record は、常に 「この product name は vulnerable である」 と同義ではありません。 実際の条件は、 「この product が、この version constraints と software context の下で vulnerable である」 に近いことが多いです。
AVM は、structured criteria を評価することで、 そのロジックを可視化したまま保ちます。 すべてを一つの score に隠したり、 product-name matching に還元したりはしません。
Practical effect: system は、「同じ family」であること、 「同じ product」であること、 そして「実際に affected condition の範囲内にあること」 を区別できます。
Version-aware evaluation
version information は、正確な matching にとって最も重要な input の一つです。 ある product family が vulnerability に関連していても、 実際に影響を受けるのは特定の vulnerable range 内だけかもしれません。
そのため AVM は、matching の一部として version conditions を評価します。 これにより、product identity だけに依存した場合に起こる false positives を減らせます。
なぜ重要か
同じ product の二つの installation でも、 installed version によって exposure は異なる場合があります。
何を防ぐか
product 名が同じというだけで、 すべてを同程度に vulnerable と見なすことを防ぎます。
Alert certainty: CONFIRMED と UNCONFIRMED
AVM では、alerts に certainty が付与されます。 これは、system がその vulnerability が software record に適用されると どの程度の確信を持って判断したかを示します。
CONFIRMED
vulnerability がその software に明確に適用されると判断された状態です。
通常は、canonical identity が解決されており、 relevant version conditions も曖昧さなく評価できたことを意味します。
UNCONFIRMED
vulnerability が適用される可能性はあるものの、 AVM が available evidence だけでは完全には確認できない状態です。
典型的には、version information が欠けている、 reliable に parse できない、 あるいは vulnerability data 側に precise confirmation に使える version constraint が定義されていない場合に起こります。
実運用では、この区別によって confirmed exposure と review がまだ必要な possible exposure を分けて扱いやすくなります。
UNCONFIRMED の典型例:
- installed software version が存在しない
- installed software version はあるが parse できない
- vulnerability record に使える version boundary がない
Key idea: CONFIRMED は、AVM が十分な精度で applicability を確認できたことを意味します。 UNCONFIRMED は、もっともらしい match は見つかったが、 full confirmation には evidence が足りなかったことを意味します。
Example
ある vulnerability が、特定の vulnerable range までの product family にのみ適用されるとします。 system には、同じ canonical product identity を持つ software があっても、 installed version はその vulnerable range の外側かもしれません。
その場合、AVM は実際に affected な version に対する結果と 同じ結果を出すべきではありません。 名前は一致していても、product は一致していても、 version condition は一致していないからです。
Uncertainty と不完全な evidence
すべての software record が、 完璧な version data や完全な canonical mapping を 初回 import 時点で持っているわけではありません。 AVM は、そのようなケースを黙って confident result に寄せるのではなく、 見えるまま保つよう設計されています。
Canonical linkage がない
software row が canonical vendor / product references に linked されていなければ、 downstream matching は不完全なままになる可能性があります。
Version evidence が弱い
version information が欠けている、ノイズが多い、 あるいは精度が低い場合、 system はその制約を result に反映すべきです。
Review surface
これらのケースは隠されません。 unresolved mappings、review workflows、 explainable matching outcomes を通じて可視化されたまま残ります。
Failure modes
Canonical mapping がない
system がその software row がどの canonical vendor / product に対応するのか 分からなければ、信頼できる matching はできません。
Version data が不十分
product identity が分かっていても、 installed version が弱い、あるいは存在しない場合は、 version-aware evaluation が制限されることがあります。
Raw naming が曖昧
raw vendor / product strings が広すぎる、ノイズが多すぎる、 あるいは不統一すぎるために、 review なしでは自動解決できないことがあります。
Target scope mismatch
名前が似ていても、 vulnerability condition が別の software context や applicability scope を 対象としていることがあります。
Alert generation
AVM の matching は、comparison が true を返しただけでは完了しません。 その operational result も記録されなければなりません。 そのため AVM は、matching cycle の一部として alert records を作成または更新します。
これにより alert state が明示的に残ります。 また、canonical linkage や matching inputs が変化した際に、 後から review、recalculation、stale-result cleanup を行うこともできます。
Operator から見える結果
AVM は、operators が final alerts だけでなく、 そこに至る path の品質も review できるように設計されています。
Resolved and matchable software
canonical linkage を持つ software rows は、 より信頼できる形で vulnerability evaluation に進めます。
Visible unresolved software
unresolved のままの software rows も、 background logic に消えるのではなく、 review 用に見えるまま残ります。
Reviewable alert state
alerts は、canonical coverage が改善するにつれて recalculated、inspected、improved できる独立した result set です。
AVM が避けようとしていること
Blind string matching
名前の類似性を、 vulnerability applicability の証拠とみなしてしまうことです。
Hidden scoring logic
applicability decisions を、 review surface の少ない opaque internal score に押し込めることです。
Overconfident results
uncertain cases や unresolved cases を、 fully established matches であるかのように見せてしまうことです。
Discarded review context
unresolved mappings、alias maintenance、recalculation workflows が持つ operational value を失ってしまうことです。
まとめ
AVM の matching は段階的な decision process です。 raw software observations から始まり、 canonical linking によって identity を安定化し、 structured vulnerability conditions を評価し、 version-aware logic を適用し、 最後に alerts として operational result を記録します。
このプロセスは意図的に inspectable になっています。 AVM は、何が resolved されたのか、 何が inferred されたのか、 何がまだ review を必要としているのかを、 operators が理解できる程度に matching path を見える形で保とうとしています。